
How are Stampede’s computing resources and computation time allocated to scientists?
As mentioned earlier, Stampede is funded through the NSF and as a result, about 90% of the computing time is allocated through a national process called XSEDE that provides the shared services for the computing centers in the US. XSEDE is run by an allocation committee, a group of experts that meets once a quarter. People write proposals through the XSEDE process to allocate the machine. Our measure is based on Xeon node core hour units, this is the service units. As we have 16 Xeon cores on a node, an hour of node time is 16 service units.
We put about 800,000,000 service unit hours a year through the XSEDE process from which 20-25,000,000 go to start-ups, that is new users who don’t get through the committee but who ask for a start-up allocation. About 175,000,000 goes to large users doing research in education requests, through the committee. We get a couple hundred new proposals through that process every quarter. Users actually request about five times as much as we have available. A little bit more than a billion hours a quarter have been requested through the last quarter and that’s expected to continue to grow. We see a lot of demand for very large systems from a pretty large number of users, but we just make the time available to XSEDE.
Can you describe one or two science projects that are currently being carried out on Stampede?
We have many exciting and very large-scale projects that I want to emphasize, among which a couple that really use the Xeon Phi. There is one with the Klaus Schulten group at the University of Illinois at Urbana-Champaign. They perform molecular dynamic simulations on biomolecules using Stampede as a computational microscope to unravel fundamental problems, such as how a “newborn” protein folds and how to design novel enzymes to produce second-generation biofuels.
They and their collaborators produce NAMD, North American Molecular Dynamics, which is a very well-known code. We had some pretty good success with that code on Xeon Phi scaling out to pretty large problems. They’re now looking at some vaccine applications.
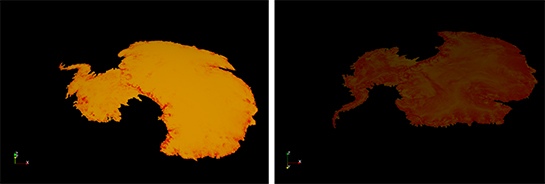
There is also a Geophysics project led by George Biros with Omar Ghattas at UT Austin. They have a code that scales at several thousands of Xeon Phi to get about 60% of Stampede peak performance. This code is at the core of a number of different scientific problems but most recently they used it to do some ice sheet modeling, looking at the flow of ice sheets over the poles, how the ice moves, speeding up or slowing down, in other words simulating the dynamics of these movements.
How is the support to users organized in terms of training, expertise and code optimization?
As an NSF resource, we work through the XSEDE project. Some of the training and user support is funded directly through the Stampede project and some of it through XSEDE. Some people here and some others at other sites help with that support as well. We provide several levels of services: for training we do both in-person and webcast courses. We also provide on-line trainings with our partner, Cornell University, called the Cornell Virtual Workshop, which is an asynchronous online demand where you get training whenever you want. We did about 35 training courses last year either directly related to Stampede or some aspects of parallel processing and visualization that you can do on Stampede. Half of those were webcasts.
We also do tutorials at major conferences, as many conference as we can, like SuperComputing or International SuperComputing. We had almost 2,000 users attend the training courses in-person or through the webcast last year and about another 10,000 through online training. We try to reach a lot of users on that.
Regarding the support through XSEDE, we run a 24 hour helpdesk and a ticket system. Lots of the folks at the HPC Group here spend a lot of time doing tickets. Some of these tickets turn out to be a very long collaboration with users to get their code running and optimized. There is the Extended Collaborative Support Service (ECSS), also funded through the XSEDE project, where we assign one of our experts to work with the user team. This is something users can request when they request compute time. But sometimes they come in and file a ticket about performance and we discover that the I/O or the file system access in the code needs to be restructured to really get good performance and to scale up any further. We might assign somebody to work with them half time, for one or six months. A small project might be 10% of a person for a month and a big project might be half of a person for a year to work with them to restructure their code. Between the Stampede project and the XSEDE project, we have the equivalent of 10 full time people working in support mode all the time to really get down deep with users and what it takes to get to Xeon Phi at scale or visualization at the petascale.
What is the background of the staff that provides this support?
Most come from either the HPC group or the Data Intensive area. Most of the people we hire in these groups do not necessarily come from a computer science background, they come from one of the application areas. We have aerospace engineers, quantum chemists, astrophysicists, biologists, a dozen of PhDs in a dozen application areas. Their primary work is in computation but they also have a foundation in various disciplines. In order to really communicate with all the users, it’s necessary to have a blend of expertise. We have some folks who are experts in simulating nuclear reactors, others in exploring reserves in oil fields and seismic modeling. We try to assign the right person to the right project, but of course everybody ends up doing some support from their own area. Having a strong science and engineering background with numerical methods really helps to communicate with users.
Stampede is a little more than one year old now. What’s the roadmap for its evolution?
As you mentioned, Stampede started in January of 2013. It was projected to have a four-year life span, so until January of 2017. We will do an upgrade when the second generation of Xeon Phi becomes available next year or early 2016. And sometime in 2017, we will compete for a Stampete-2 machine, a renewal system that will replace all the hardware. This machine will be based on a review of the current system and how successful we are and the availability of funding.
In the same respect, what’s your vision of TACC’s next supercomputer?
We run several systems here, but our very next supercomputer, which will be available to users in the fall of this year, is Wrangler. Wrangler is a different take as it runs a complementary capability next to Stampede. It really focuses on large scale data applications with a big flash component to do I/O at a terabyte a second. It is a much smaller system than Stampede in terms of number of processors, but it has much larger I/O capabilities. We will be able to stream data through a node at about 400 times the way we can on Stampede. Stampede has a really amazing file system but it’s about 150 GB/second. Wrangler will be only about a hundred nodes but will have a terabyte/second performance that will be more efficient to do small transactions. We designed Stampede for doing very large I/O, big files and big MPI programs. Wrangler will support the Hadoop framework and other things as well. We are very excited about this machine as it will be able to bring different kinds of applications in 2015.
So, when you look at the timeframe of Stampede 2 – that will replace the current Stampede in 2017-2018 – we will see how elements of Wrangler handle data comparatively. There will be a migration from PCI-based accelerators to self-hosted accelerators. The difficulty will be to determine the mix between self-hosted accelerated nodes and more traditional nodes, because we want to support the very wide range of users that we have and help them run all the different applications in all the different fields of science. What we call accelerators now will be in the main nodes.
Do you personally expect a first generation of exascale machines to be available and scientifically operational by 2020?
Yes I do. The Exascale has some special challenges. The first Terascale machine was 1998, the first Petascale machine was 2008, and we might have an Exascale machine earlier, in about 2018. There will be a machine whose peak performance is over one Exaflops during or before 2020. I feel pretty confident of that. The real question is how usable will that machine be? Making a Linpack benchmark at one Exaflops will happen in that time frame. Will it be a balanced system that is as good for science as the systems that we currently have at the petascale in that time frame? This might require a lot of work. We’ll see our benchmarks evolve to more properly measure balanced performance. There are efforts to do that already on the way. I’m nor certain that we will be focused on the Linpack benchmark in 2020 as we are today.
What hardware and software challenges do you see as prominently difficult with regard to the next generation of highly parallel machines?
There is a software challenge that is the big change. This is what we see today with the Xeon Phi or the GPUs. We have to extract the parallelism from the code. In every generation, we’ve said that the challenges were both in hardware and software but, in truth, most of the work ended up being in the hardware to get from Terascale to Petascale. In 1998, code was mostly big distributed memory MPI code written in C or FORTRAN. In 2008, about the same MPI code with few enhancements was able to sustain one Petaflops. This is natural because the life cycle of software has long been compared to the life cycle of hardware. But at this point we need to get to vectorization. All of the parallelism is not an option anymore.
The Exascale will also be MPI and OpenMP code. This code is already written, it will not be totally re-written in the next five years. But the work we are doing now to support vectorization and to support additional threading in order to deal with GPUs or the Xeon Phi will pay for the next Exascale machines. The code that ignores these levels of parallelism will continue to get a lower and lower fraction of peak on those machines. We are already seeing that, the less well-written code, perhaps in a non-traditional language today, are not expertly parallel and get below 1 % of peak performance on a lot of machines.
So, from a hardware perspective, we are going to get there on this roadmap. We will get rid of the PCI cards to move everything onto the motherboard, we will continue to have more performance with more concurrency at each node. We will have hundreds to thousands of threads per node of floating point units. The question will be whether we can make enough of the software to keep up to justify the big investment in these machines…
More around this topic...









© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















{kind=link}
{kind=link}
{kind=link}