
Computational Aspects
Efficiently deploying simulations where thousands of electrons carry out billions of step requires that the most critical algorithmic and data processing aspects be optimized as much as possible. So let us now detail our main strategies.
We start by defining a walker as the set of x, y and z coordinates of each one of N electrons of the system (a vector with 3 N dimensions). To accomplish a trajectory, a walker will carry out a random motion in the 3 N dimensional space, in order to reconstruct the probability density corresponding to the square of the wave function.
We also define a block (Fig. 1) as a set of short trajectories carried out by a group of walkers during a certain number of steps (about 10,000). For each block, the average values of the properties is computed (energy, dipole moment, etc.) from the successive positions of each walker along all the trajectories of the block. If the blocks are sufficiently long, the final positions of the walkers are completely decorrelated from the initial positions, so the blocks can be considered to be independent. In this case, the average computed values on the blocks have a statistical distribution following a Gaussian law. Each block average is a sample that is used to statistically compute the average values of the properties.
The aim is then to compute as many blocks as possible, as fast as possible. For that, we have adopted two strategies. The first one is setting up an effective parallelization system. The second one is reducing the calculation time of each block by working on single core optimization.
Managing Resilience
With tens of thousands of cores, failure tolerance becomes a new concern. If a computation node breaks down at the end of five years on average, a system with 2,000 nodes has an intrinsic MTBF of about 24 hours. We must then have a system that survives no matter what.
In deterministic algorithms, the calculation is broken down into a number of tasks, each one of them essential for a correct result to be obtained. In a failure event, some of these tasks won’t be carried out and the entire calculation will be lost.
MPI libraries are well adapted to deterministic calculations. When one MPI client does not respond any longer, the rest of the simulation is lost – as it should. In our model, losing blocks during simulation does not change the averages: it only affects the result’s error bar. We thus have chosen not to use MPI for parallelization. Instead, we have implemented a client/server model where clients calculate blocks and send results to the server, which stores them in a database. If one of the client dies, never mind, the others continue with their calculations.
The clients and servers are multithreaded Python scripts communicating by TCP sockets (Fig. 2). As communications are nonblocking and not very intensive, TCP layer latencies are not a problem. Note that there is a single client per computation node. Each client launches as many calculation programs as there are physical cores on the node. The calculation program is a monothread Fortran binary connected to the client by a Unix pipe. As soon as results are sent to the client, the calculation program immediately starts working on the following block. When the client is inactive, it sends its results to another client so they can be forwarded to the server.
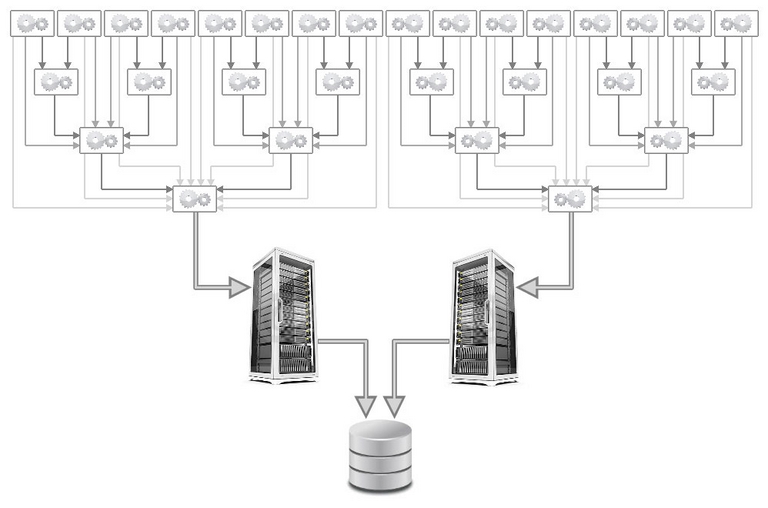
Fig. 2 – Clients are organized as a binary tree to alleviate network communications : a client sends its results buffer to its parent in the tree. When the parent receives data coming from one of its children, it adds them to its own results buffer, which later on will be sent to its parent (the grand parent), etc. The server thus receives a small number of large results packages instead of a large number of small packages. Resilience: if a parent doesn’t respond, the client sends its results buffer to the grand parent. If the grand parent doesn’t respond either, the client sends its results to the great grand parent and so on, until the packages ends up being sent to the data server.
The server comprises two main threads: a network thread and an I/O thread. Data is received by the network thread. It is then processed and put in a queue. At the same time, the I/O thread empties the queue to save the results to disk. Clients never access the local hard drive or the shared file system but a virtual RAM drive (/dev/shm) to prevent failures connected with temporary storage (disk full, physical breakdown, etc.).
More around this topic...








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.





















