
(Cet article fait partie de notre dossier HPC Dans Le Cloud)
Avec plus de 60 % de part de marché mondiale dans l’Infrastructure as a Service, Amazon s’est intéressée très tôt au segment du calcul intensif. C’est elle, pour ainsi dire, qui a inventé le cloud computing avec EC2, son offre d’instances serveurs à la demande lancé en 2006. Une plateforme qui, année après année, n’a cessé d’innover. Dès 2007, la demande était telle qu’Amazon a dû créer des instances large et extra-large disposant de plus de mémoire, de CPU plus puissants et d’un stockage au niveau du nœud. L’arrivée de Red Hat Linux, d’OpenSolaris, puis de Windows Server sur EC2 allait ensuite permettre à de nombreuses startups d’y héberger leurs services mais aussi d’y lancer des calculs de type Big Data via Amazon Elastic MapReduce. En 2009, conscients de l’arrivée de besoins croissants en calcul intensif, les responsables d’AWS commencent à proposer des instances aux capacités accrues : 32 Go de RAM, 4 cœurs virtuels et 850 Go de stockage pour le double extra-large, et deux fois plus de ce qui précède pour le quad extra-large – avec en même temps des tarifs revus à la baisse. Il faut toutefois attendre 2010 pour que la notion de cluster apparaisse au catalogue : l’objectif est alors de grouper les instances EC2 pour disposer d’une bande passante plus élevée entre les nœuds et permettre ainsi l’exécution d’applications plus ou moins massivement parallèles. Les groupes d’emplacements annoncés par Amazon garantissent une bande passante non-bloquante de 10 Gbit/s entres les instances du groupe. 2010 est également l’année où AWS déploie des accélérateurs NVIDIA Tesla, pour permettre l’exécution de codes CUDA ou OpenCL. Depuis, quasiment chaque année, Amazon n’a eu de cesse de proposer des instances plus puissantes et de baisser ses prix, ce qui explique son impressionnant portefeuille de clients HPC.
“La majorité de nos clients viennent au cloud pour compléter une infrastructure HPC existante par de la puissance additionnelle” explique David Pellerin, Business Development Manager. “Grâce au mode burst, la gestion des pics de puissance est un cas d’usage typique d’Amazon Web Services. Mais on voit de plus en plus de grosses charges de calcul venir dans le nuage.”
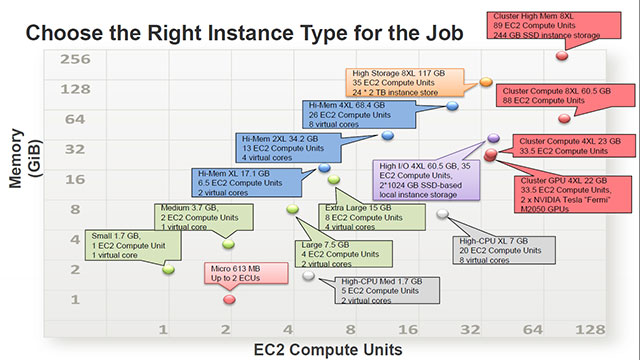
Le portefeuille d’instances virtuelles actuellement au catalogue d’Amazon Web Services.
Le HPC a la particularité de présenter une grande variété dans les workloads. “Pour certains, les utilisateurs sont dans l’approche scale-out, tandis que d’autres préfèrent la mise en parallèle des calculs. Alors, plutôt que d’acheter un nouveau cluster ou d’étendre un cluster existant, réaliser un scale-out dans le cloud est une option valable. Et dès que l’avantage du cloud en termes de coûts et de très forte capacité de montée en charge est bien intégré, les clients commencent à songer à de nouvelles applications. Quand toutes les données sont à un seul endroit, quand vous disposez de toute cette puissance dimensionnable à la demande, alors vous pouvez passer à de nouveaux modèles économiques, un peu comme ce fut le cas avec Hadoop.”
Parmi les références client citées par AWS figurent naturellement bon nombre de startups Internet. C’est le cas de Foursquare qui analyse avec MapReduce cinq millions de check-ins quotidiens sur son réseau social géolocalisé, de Topsy qui analyse les conversations sur les réseaux sociaux ou encore de Scribd, qui réalise ses conversions de documents via EC2. Mais, à côté de ces applications purement Big Data, des industriels et des universités ont également recours à Amazon pour réaliser des simulations numériques beaucoup plus proches des usages HPC traditionnels. On peut citer le projet mené par AeroDynamic Solutions qui, pour le compte d’un motoriste américain, a récemment évalué l’efficacité aérodynamique d’un profil de turbine destinée à l’US Air Force. Le maillage initial de plus de dix millions d’éléments a été divisé en 40 blocs sur lesquels le calcul CFD a été effectué en parallèle sur un cluster cloud de 40 nœuds. Le code de simulation a calculé 10 500 étapes avec 20 itérations par étape sur les 40 processeurs en simultané. L’ensemble des échanges a été sécurisé par VPN. Les résultats ont été obtenus au bout de 72 heures de calcul, pour un coût global inférieur à 1 000$.
Le cas de Pfizer, autre client d’AWS, préfigure assez bien le rôle que peut prendre le cloud dans la stratégie HPC d’un industriel global. Le laboratoire utilise en effet le service Amazon Virtual Private Cloud pour compléter son cluster de calcul interne, une extension dont l’interface et la sécurisation ont demandé pas moins de sept mois de travail. Mais l’effort s’est révélé payant. Amazon et l’équipe HPC de Pfizer ont en effet décroché la certification SAS 70 Type II, un standard d’audit des datacenters requis dans les secteurs de la finance et pharmaceutique. Plus concrètement, Pfizer a modifié son ordonnanceur de tâches pour le rendre pleinement compatible EC2. Ainsi, lorsque des calculs sont envoyés dans le cloud, c’est lui qui monte automatiquement les instances puis les éteint après exécution, afin de ne devoir à Amazon que le strict temps de calcul utilisé. D’après Michael Miller, Directeur de Pfizer Global R&D cité par nos confrères de TechTarget, 80 % de la puissance requise sur les nouveaux projets est désormais fournie par Amazon, soit la moitié de la puissance totale de calcul consommée par Pfizer R&D. Selon les consultants Deloitte, l’économie générée par cette approche atteindrait 600 M$, soit 7 % du budget R&D du laboratoire ! Bénéfice annexe, l’équipe HPC est désormais en mesure de calculer le coût réel d’une simulation et de présenter la note au chercheur, qui va ainsi pouvoir prioriser ses demandes en fonction des budgets alloués à chaque projet.
(Dossier HPC Dans Le Cloud : article précédent | suivant)
More around this topic...
Related articles








© HPC Today 2024 - All rights reserved.
Thank you for reading HPC Today.






















{kind=link}